在当前数字化、智能化的时代浪潮中,工业大数据已成为推动制造业转型升级与价值创造的核心引擎。清华大学软件学院王建民院长在其关于“工业大数据技术与应用”的深入阐述中,系统性地揭示了大数据技术与软件技术开发深度融合所催生的新范式、新挑战与新机遇。
一、工业大数据:内涵、特征与价值维度
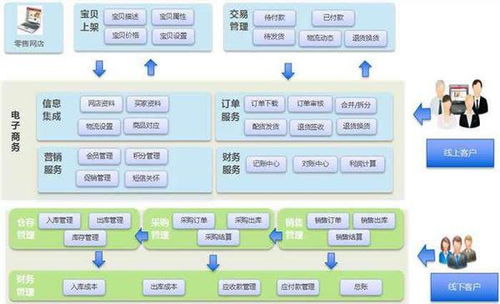
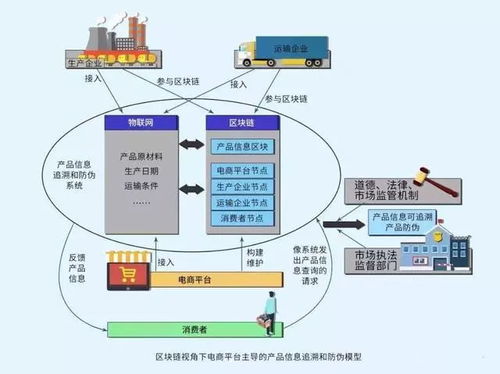
工业大数据并非传统企业数据的简单扩容,而是指在工业研发设计、生产制造、经营管理、运维服务等全生命周期环节中产生的海量、多源、异构、时序的数据集合。其核心特征表现为“4V+1C”:Volume(体量巨大)、Variety(种类繁多)、Velocity(生成快速)、Value(价值密度低但潜在价值高),以及至关重要的Contextual(强上下文关联性)。王建民院长指出,工业大数据的价值实现,关键在于从单纯的“数据积累”转向“知识提炼”与“智能决策”,其价值维度覆盖了优化生产流程、预测设备故障、创新商业模式、赋能产品服务化转型等多个层面。
二、核心技术栈:软件技术开发的基石重构
面向工业大数据的处理与应用,软件技术开发的基础架构与工具链正在经历深刻变革。王建民院长重点剖析了构成工业大数据技术栈的关键层:
- 数据采集与集成层:需要开发适配多种工业协议(如OPC UA、MQTT)的边端采集软件,并解决多源、异构数据的实时同步与高质量集成问题。
- 数据存储与管理层:分布式文件系统(如HDFS)、时序数据库(如InfluxDB、TDengine)以及数据湖技术的应用,对软件的数据建模、索引优化、生命周期管理能力提出了新要求。
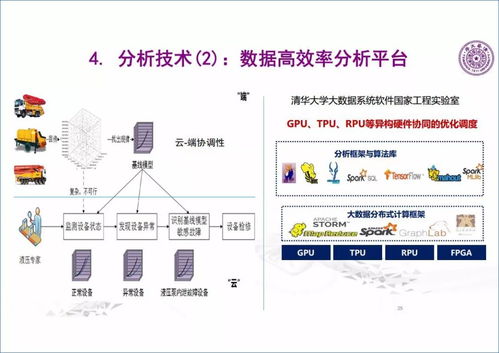
- 数据处理与分析层:批流融合计算框架(如Apache Flink、Spark)成为主流,软件开发者需掌握大规模分布式计算下的编程模型与性能调优。
- 数据建模与智能层:集成机器学习(尤其是深度学习、迁移学习)、机理模型与专家知识的混合建模平台开发,是软件实现工业知识沉淀与复用的关键。
- 数据可视化与应用层:面向特定工业场景(如数字孪生、产线看板)的高交互、实时渲染的应用软件开发,强调用户体验与业务洞察的直观呈现。
三、应用驱动开发:从场景到落地的软件工程实践
王建民院长强调,工业大数据软件技术的生命力在于应用落地。他通过典型案例如预测性维护、能源优化、供应链协同等,阐明了“场景驱动”的开发方法论:
- 需求精准化:软件需求分析必须深入工厂车间,与工艺、设备专家深度融合,将模糊的业务问题转化为可计算、可建模的数据科学问题。
- 架构柔性化:采用微服务、容器化(如Docker/Kubernetes)的云原生架构,以支持快速迭代、弹性伸缩和复杂系统的解耦与集成。
- 模型产品化:将数据分析模型以标准化、可配置的软件组件或服务(Model as a Service)形式进行封装和管理,实现模型的持续训练、部署与运维(MLOps)。
- 安全与可信贯穿始终:工业软件需内置数据安全、网络安全和模型可信保障机制,确保数据主权、过程可靠与决策可解释。
四、未来展望:软件人才的培养与生态构建
面对工业大数据带来的广阔前景,王建民院长认为,未来的软件技术开发者需要具备“工科思维、数据思维、软件思维”的三重素养。清华大学软件学院等教育科研机构,正致力于培养既精通先进软件技术,又深刻理解工业流程与业务的复合型创新人才。构建开放协同的工业软件开源生态与产业联盟,对于降低技术门槛、加速解决方案成熟、推动中国工业软件自主可控发展具有战略意义。
王建民院长的论述清晰地表明,工业大数据时代下的软件技术开发,已从传统的工具实现角色,跃升为工业知识载体、智能核心引擎以及业务价值创造者。这一转型要求软件技术与工业技术更深层次地交织,以数据和算法为纽带,驱动工业迈向智能化、服务化的未来。